DeepSeek lanza la vista previa de V4 con hasta 1 millón de tokens de contexto y dos modelos abiertos
por Edgar OteroDeepSeek ha anunciado la llegada de DeepSeek-V4 Preview, una nueva familia de modelos abiertos con la que la compañía china vuelve a poner el foco en dos de sus argumentos habituales: contexto muy amplio y costes más contenidos. El lanzamiento incluye dos variantes, DeepSeek-V4-Pro y DeepSeek-V4-Flash, ambas con una ventana de contexto de hasta 1 millón de tokens, según detalla la propia empresa en su informe técnico.
En concreto, DeepSeek presenta V4-Pro con 1,6 billones de parámetros totales y 49.000 millones de parámetros activos, mientras que V4-Flash baja a 284.000 millones totales y 13.000 millones activos, manteniendo el mismo contexto máximo de 1 millón de tokens. La compañía los ofrece ya en su chatbot bajo dos modos distintos y también ha actualizado su API desde hoy.
La novedad importante no es solo el tamaño de la ventana de contexto, sino cómo DeepSeek intenta hacerla viable desde el punto de vista técnico. En el documento, la empresa explica que V4 introduce una arquitectura híbrida de atención para comprimir mejor el trabajo con secuencias muy largas y reducir tanto el coste de inferencia como la memoria necesaria para mantener el contexto.
¿Qué promete DeepSeek con V4?
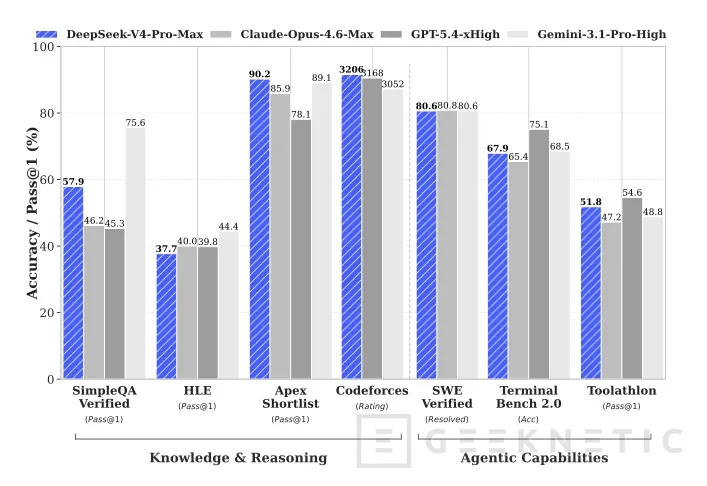
Según DeepSeek, el nuevo modelo mejora especialmente en razonamiento, programación y tareas de agentes, tres frentes que se han vuelto clave en la carrera actual de la inteligencia artificial. En su informe, la empresa sostiene que DeepSeek-V4-Pro-Max supera a sus predecesores en tareas centrales y que, en escenarios de 1 millón de tokens, DeepSeek-V4-Pro requiere el 27% de los FLOPs por token y el 10% de la caché KV frente a DeepSeek-V3.2, mientras que V4-Flash reduce esas cifras todavía más.
Todo esto encaja bastante bien con la identidad que DeepSeek se ha construido en poco más de un año. La compañía es sinónimo de modelos competitivos, abiertos y con una narrativa muy marcada de eficiencia frente a los gigantes estadounidenses. Esa imagen ya quedó bastante definida cuando analizamos cómo funciona DeepSeek y por qué había puesto en jaque a la industria, sobre todo tras el impacto que causó R1 por su relación entre coste y rendimiento.
De hecho, ese factor económico sigue siendo central en cualquier anuncio de la compañía. DeepSeek insiste en hablar de una nueva era de contexto largo rentable, aunque por ahora no ha detallado públicamente cuánto ha costado entrenar V4 ni con qué hardware exacto se ha desarrollado. Ese silencio no es menor, porque la empresa ya arrastra dudas desde 2025 sobre los recursos reales detrás de sus modelos, en línea con las sospechas que surgieron cuando se habló de que el éxito inicial de DeepSeek podría haber requerido decenas de miles de H100 de NVIDIA.
Un paso más en la estrategia que hizo despegar a DeepSeek
Más allá de las cifras, el lanzamiento de V4 refuerza la estrategia de la compañía china, que no es otra que ofrecer modelos de alto nivel con pesos abiertos y acceso amplio, algo que sigue diferenciando a DeepSeek frente a muchas propuestas de OpenAI, Anthropic o Google. Ese planteamiento es parte de lo que ha hecho que la compañía gane tanta notoriedad en tan poco tiempo.
Ahora bien, conviene mantener cierta cautela. Como ocurre con casi todos los lanzamientos recientes en IA, la mayoría de las comparativas proceden de la propia compañía y se apoyan en benchmarks o en condiciones muy controladas. Aun así, la llegada de DeepSeek-V4 sí parece relevante por una razón concreta: vuelve a empujar la idea de que el contexto largo no tiene por qué quedar reservado a los modelos cerrados más caros. Y ese mensaje, viniendo de DeepSeek, sigue siendo una presión incómoda para el resto del sector.
Fin del Artículo. ¡Cuéntanos algo en los Comentarios!