Samsung presenta TRUEBench un benchmark con 12 idiomas para medir la productividad real de la inteligencia artificial
por Manuel Naranjo Actualizado: 26/09/2025La IA ya no vive en el laboratorio. Está en correos que resumimos a toda prisa, en informes que pedimos que sinteticen y en hojas de cálculo que alguien tiene que interpretar sin perder contexto. El problema es que la mayoría de benchmarks siguen midiendo otra cosa: respuestas de un turno, casi siempre en inglés, con pruebas pensadas para lucir modelo más que para trabajar con él. Ahí es donde Samsung sitúa TRUEBench, un banco de pruebas “de verdad” (así lo presenta) que intenta valorar la productividad de los LLM en situaciones reales.
Qué mide exactamente y por qué es distinto
TRUEBench nace de usos internos de Samsung para tareas de oficina y soporte. No se queda en acertijos: agrupa 10 categorías y 46 subcategorías que van desde generación de contenido, síntesis y análisis de datos hasta traducción, con 2.485 conjuntos de pruebas.
Las entradas no son todas iguales: hay desde solicitudes de 8 caracteres hasta resúmenes que superan los 20.000, lo que obliga a los modelos a sostener coherencia, memoria y tono durante varios pasos. Ese detalle es importante porque la productividad no es solo “acertar”, sino mantener el hilo y entregar algo útil cuando la tarea se complica.
Multilingüe y con cruces entre idiomas
Otro punto que rompe inercias: el banco no es monolingüe. Incluye 12 idiomas (chino, inglés, francés, alemán, italiano, japonés, coreano, polaco, portugués, ruso, español y vietnamita) y, además, escenarios interlingüísticos. En un mundo donde el documento llega en un idioma, la fuente en otro y la entrega final en un tercero, esa mezcla refleja mejor el trabajo cotidiano que una lista de preguntas en inglés con respuestas tipo test.
Cómo evalúa y por qué importa el método
La corrección combina personas e inteligencia artificial. Primero, anotadores humanos definen criterios; después, una IA revisa incoherencias, atajos o restricciones mal planteadas; al final, los humanos refinan lo que no encaja. Con esa rúbrica verificada, la evaluación es automática, pero más estricta: para aprobar, el modelo debe cumplir todas las condiciones de la tarea. La idea es reducir el sesgo y, sobre todo, evitar premios a respuestas que “suena que sí” pero se saltan requisitos implícitos, algo muy habitual en flujos reales.
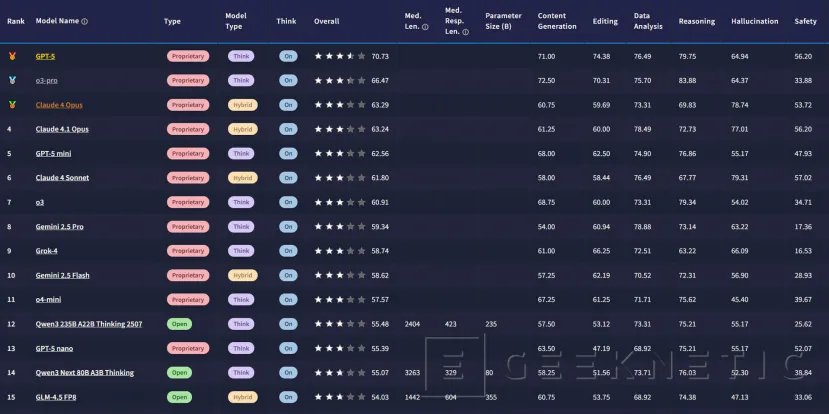
Clasificaciones abiertas y foco en eficiencia
Samsung publica muestras y tablas en Hugging Face. Se pueden comparar hasta cinco modelos y, junto a la puntuación, aparece la longitud media de las respuestas. Ese dato, a menudo olvidado, es clave: dos modelos pueden empatar en calidad, pero no es lo mismo entregar 300 palabras útiles que 1.200 rodeos. En productividad, precisión y concisión pesan lo mismo que la creatividad.
Qué acierta y qué inquieta
TRUEBench acierta al cambiar el foco: medir tareas completas, diálogo de varios turnos y multilengua. Aporta, además, una forma de evaluación que intenta blindarse frente a trucos y deja menos espacio al “parece correcto”. Ahora bien, también deja preguntas.
Es un benchmark patentado: depender del custodio para su evolución puede frenar adopción si la comunidad no percibe suficiente transparencia. La evaluación automática, por buena que sea la rúbrica, siempre corre el riesgo de que los modelos aprendan a optimizar para el examen. Y el multilingüe exige mantener actualizados corpus y criterios, algo costoso si se quiere evitar que un idioma quede mejor cubierto que otro.
Dónde encaja en el mapa de la IA de empresa
El lanzamiento llega cuando las compañías piden métricas que conecten con su día a día. TRUEBench no pretende sustituir a los benchmarks clásicos (siguen siendo útiles para medir capacidad general), sino llenar el hueco entre “qué tan listo es un modelo” y “qué tan útil resulta cuando tiene que trabajar”. Que Samsung Research impulse esto encaja con su posición: diseña hardware, integra servicios y, cada vez más, ofrece herramientas para que la IA sea productiva y no solo espectacular en una demo.
Lo que viene a partir de aquí
Si la industria lo adopta, TRUEBench puede empujar a los proveedores a mejorar memoria operativa, manejo de instrucciones largas y fidelidad a requisitos, justo lo que más se echa en falta cuando un LLM aterriza en un flujo de trabajo. Para ganarse esa posición tendrá que mantener rondas públicas de revisión, abrir más conjuntos de prueba y asegurar paridad entre idiomas. Si lo logra, el impacto será tangible: menos pilotos eternos, más despliegues que se justifican por resultados.
TRUEBench pone el foco en algo importante: medir si un modelo sirve para trabajar. Con tareas variadas, multilengua y una evaluación que obliga a cumplir condiciones, Samsung intenta convertir la productividad en algo cuantificable y comparable. No es la última palabra (ningún benchmark lo es), pero sí un movimiento en la dirección correcta: pasar de la brillantez de laboratorio a métricas que resisten un lunes cualquiera en la oficina.
Fin del Artículo. ¡Cuéntanos algo en los Comentarios!