


Introducción
Recientemente ha tenido lugar el lanzamiento de las nuevas GPU Ampere A100, las cuales no están orientadas a productos de consumo, pero marcan un punto de referencia de lo que podremos ver en un futuro en cuanto a esta arquitectura se refiere, la cual ha demostrado ser extremadamente capaz en el campo de los centros de datos, al menos en cuanto a cifras se refiere.
Esta arquitectura llega para sustituir a Volta, la anterior arquitectura para tarjetas GPGPU de la compañía, y tal como pudimos ver en las diapositivas de su presentación, lo hace con unas cifras de rendimiento muy superiores a lo que teníamos hasta ahora, hasta el punto de que, en el caso de la GPU Ampere A100, cada una de las 7 divisiones de la GPU en el modo MIG cuenta con el rendimiento completo de una tarjeta NVIDIA Volta V100.

A día de hoy solo existe la GPU Ampere A100, que como ya hemos comentado, no es un producto para el mercado de consumo doméstico, pero se espera que Ampere llegue a la próxima generación de tarjetas gráficas NVIDIA GeForce para sustituir a la actual NVIDIA Turing, que nos trajo características como los Tensor Cores y RayTracing en tiempo real a la gama doméstica de tarjetas gráficas de la marca.
Es de esperar que, si bien probablemente no será un salto en rendimiento tan extremadamente marcado como lo ha sido en el espacio de GPGPU, veamos interesantes mejoras en cuanto a rendimiento en juegos cuando Ampere llegue al espacio consumidor, ya sea en juegos mediante rasterizado tradicional o en juegos que hagan uso de la tecnología de RayTracing en tiempo real, así como de técnicas como DLSS 2.0 que ya vimos en el pasado.
NVIDIA Ampere en escritorio
Cuando NVIDIA lanzó Volta, separó su arquitectura de gráficas en dos gamas principales diferenciadas, una para computación, con gráficas basadas en las GPU Volta como las Tesla V100, y otras arquitecturas distintas para gráficas de escritorio, tanto para jugadores (GeForce) como para profesionales del diseño, CAD, etc (Quadro) basadas en las arquitecturas Pascal y Turing.
No obstante, existió la NVIDIA Titan V, un modelo muy exclusivo y limitado dedicado al sector entusiasta de escritorio que, como excepción, utilizaba la arquitectura Volta, eso sí, con un precio de 3.100 Euros y que no dejaba de ser una excepción, ya que, posteriormente, tanto las gamas GeForce RTX como GeForce GTX y las RTX Titan y Titan X llegaron con turing y pascal respectivamente con un mayor rendimiento.

Por ello, si NVIDIA mantiene esta estrategia, las GPU Ampere sustituirán a Volta en el mercado de GPGPU, pero no deberían al escritorio de manera generalizada. Sin embargo, como ya hemos comentado anteriormente, han surgido en los últimos meses varios rumores e informaciones relacionadas con las GPU GA104, GA103 y GA102 para GeForce y Quadro de escritorio basadas en arquitectura Ampere para sustituir a las gamas de escritorio basadas en Turing y Pascal.
Si bien no ha habido ningún anuncio oficial al respecto, algunas de estas filtraciones hablan ya de modelos concretos, por ejemplo, veíamos como una hipotética NVIDIA GeForce RTX 3080Ti contaría con 8192 núcleos, que es el total con el que cuenta la arquitectura Ampere al completo, y modelos como las RTX 3080 lo harían con 3.840 CUDA Cores de arquitectura Ampere.
Asimismo, algunas filtraciones han resultado ser ciertas, pues por ejemplo NVIDIA sí ha empezado a lanzar Ampere en la primera mitad del año, dándonos esperanzas para un posible lanzamiento de nuevas tarjetas gráficas GeForce RTX 3000 este mes de junio, aunque no es totalmente seguro pues, como ya hemos dicho, no existe ningún anuncio oficial al respecto.
Arquitectura
La arquitectura Ampere para centros de datos llega con un enfoque muy marcado en inteligencia artificial y aprendizaje profundo, tal y como pudimos ver en su presentación, y parte de ello tiene que ver con cómo se componen los núcleos en el interior de esta GPU, siendo un ejemplo muy claro la aparición de la tercera generación de los Tensor Core, con un rendimiento mucho mayor que los Tensor Core de anterior generación que podíamos encontrar por ejemplo en las GPU Volta.
La GPU Ampere al completo se compone de los siguientes elementos, los cuales podremos ver también en la imagen bajo estas líneas:
- 8 GPCs (GPU Processing Clusters), 8 TPCs (Texture Processing Clusters) por cada GPC, 2 SMs por cada TPC, 16 SMs por cada GPC, 128 SMs para la GPU al completo
- 64 FP32 CUDA Cores por cada SM, 8192 FP32 CUDA Cores para la GPU completa
- 4 Tensor Cores de tercera generación por cada SM, 512 Tensor Cores de tercera generación para la GPU completa
- 6 pilas HBM2 conectadas a 12 controladores de memoria de 512 bits
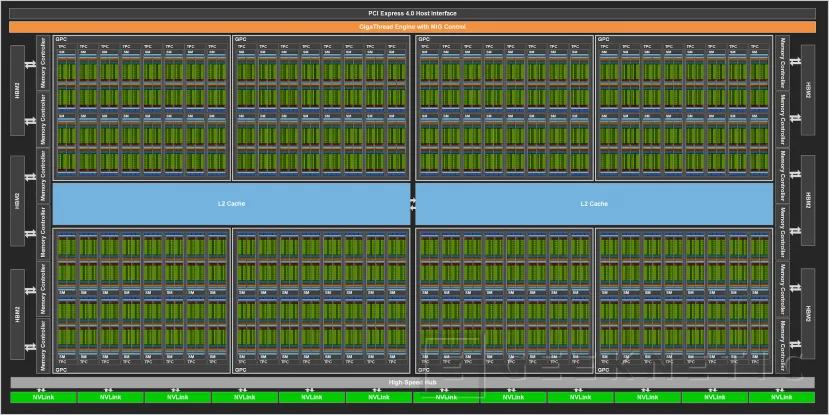
Estos 8192 núcleos ya con una primera señal de que nos encontramos ante un chip enorme, lo suficiente para que ni siquiera el recién presentado Ampere A100 haga uso del diseño Ampere al completo, contando entonces con las siguientes características:
- 7 GPCs (GPU Processing Clusters), 7 u 8 TPCs (Texture Processing Clusters) por cada GPC, 2 SMs por cada TPC, hasta 16 SMs por cada GPC, 108 SMs para la GPU Ampere A100
- 64 FP32 CUDA Cores por cada SM, 6912 FP32 CUDA Cores para la GPU Ampere A100
- 4 Tensor Cores de tercera generación por cada SM, 432 Tensor Cores de tercera generación para la GPU completa
- 5 pilas HBM2 conectadas a 10 controladores de memoria de 512 bits
De cualquier modo, las características de cada componente se mantienen invariables, encontrando para empezar una nueva arquitectura en los Stream Multiprocessors de la GPU que permite aumentar el rendimiento basándose en características que podemos encontrar tanto en Turing como en Volta, y añadiendo nuevas características encima de esta base.
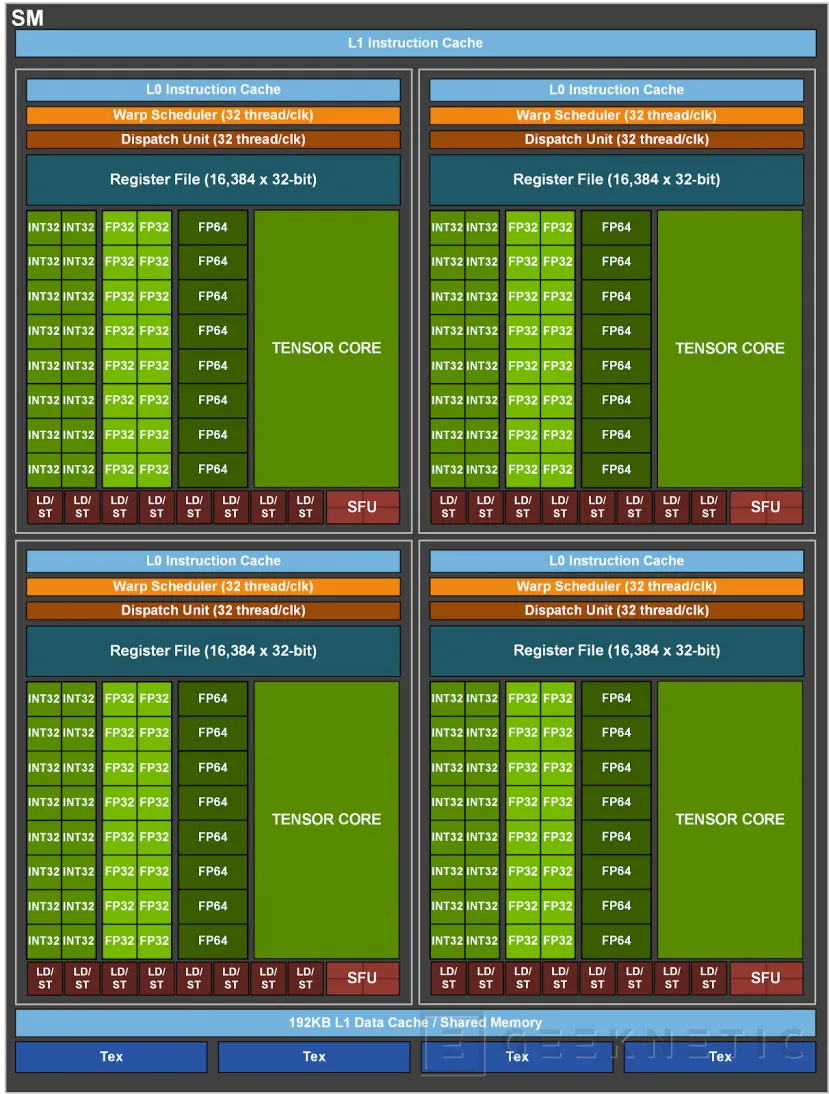
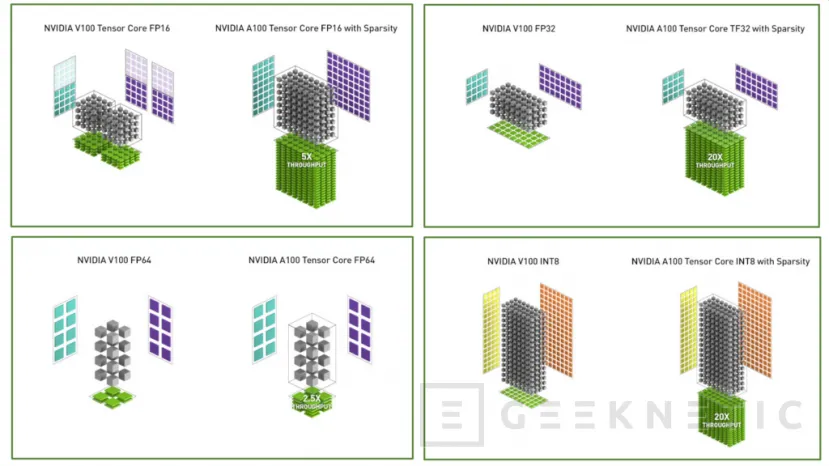
Los ya mencionados Tensor Cores de tercera generación cuentan con aceleración para todos los tipos de datos, incluidos FP16, BF16, TF32, FP64, INT8, INT4 y binario. Asimismo, su capacidad para trabajar con matrices dispersas permite doblar el rendimiento en operaciones con los Tensor Cores, algo que permite acelerar en gran medida las redes de aprendizaje profundo en inteligencia artificial.
Como muestra de las capacidades de los nuevos núcleos, NVIDIA asegura que las operaciones FP32 se ejecutan 10 veces más rápidas en el modo TF32 en su formato estándar en los nuevos Tensor Cores de Ampere, así como 20 veces más rápidas si aprovechamos su capacidad de trabajar con matrices dispersas. Del mismo modo, las operaciones FP64 son capaces de ejecutarse 2.5 veces más rápido que en las anteriores NVIDIA Volta V100, mientras que las operaciones de inferencia a través de INT8 son también 20 veces más rápidas en la nueva GPU.
Los Stream Multiprocessors de la arquitectura Ampere también cuentan con otras novedades. Entre ellas encontramos 192KB de memoria combinada compartida y caché L1, algo 1.5 veces más grande que lo que encontramos en los SM de la NVIDIA Volta V100. También se hace uso de una nueva instrucción de copia asíncrona que permite cargar datos directamente desde la memoria global hacia la memoria compartida, sin tener que hacer uso obligado de la caché L1 o de archivos de registro intermedio.
Modo TensorFloat-32 mediante Tensor Cores
En el apartado anterior hemos comentado el modo TensorFloat-32, también abreviado como TF32, en el cual nos permite acelerar trabajos de precisión simple con velocidades hasta 20 veces mayores a los métodos tradicionalmente empleados a la hora de realizar aprendizaje profundo con GPGPU.
TF32 es un nuevo modo de cálculo en las GPUs NVIDIA A100 para gestionar la matriz de operaciones, también llamadas operaciones tensor, que se usan en el núcleo de las operaciones necesarias para inteligencia artificial y algunas cargas HPC.
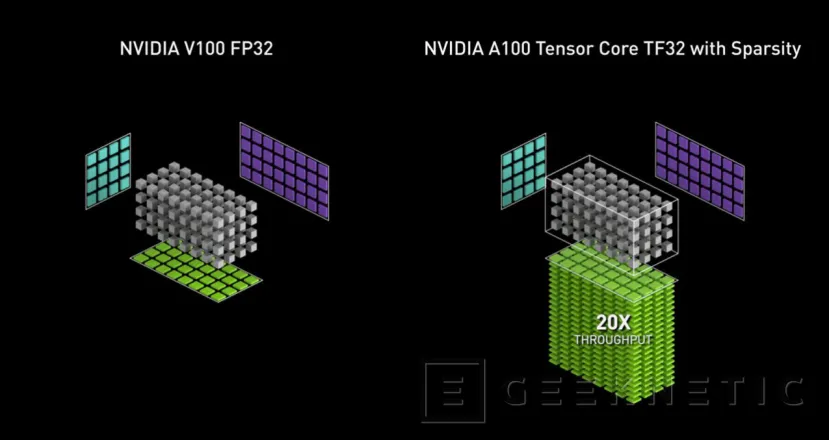
Que las operaciones TF32 funcionen sobre los Tensor Cores significa que no se usa un tipo genérico de hardware para hacer estos cálculos, sino que son núcleos especializados los que se van a encargar de realizar las operaciones FP32 derivadas de una matriz de operaciones, algo que permite aumentar la velocidad en hasta 10 veces respecto al rendimiento que se puede obtener en FP32 en una NVIDIA Volta A100, y en hasta 20 veces si combinamos el modo TF32 con las capacidades de gestionar matrices dispersas incluidas en esta arquitectura.
En el mundo real, una GPU A100 es capaz de obtener 6 veces más rendimiento que una NVIDIA Volta V100 a una velocidad de más de 1200 secuencias por segundo en BERT-Large Training FP32. Por su parte, en FP16 las distancias se reducen, pero aun así contamos con 3 veces más rendimiento que una V100 con una velocidad de unas 2300 secuencias por segundo.
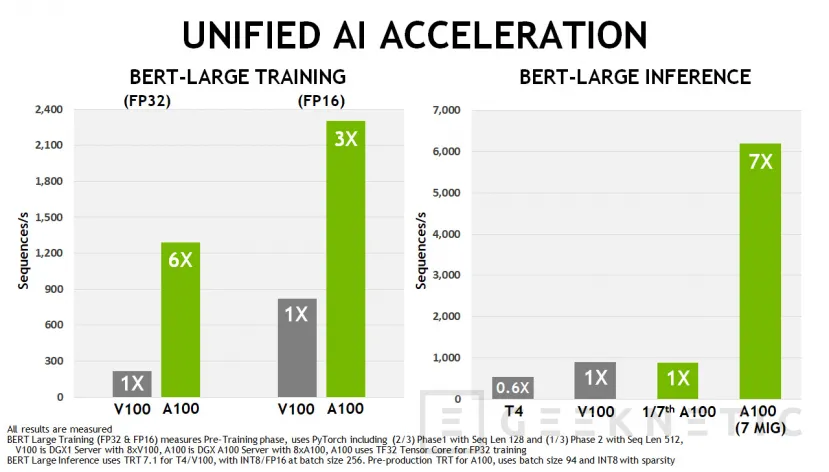
Se espera que las principales aplicaciones para este tipo de cálculos, como serían PyTorch o Tensorflow reciban soporte para TF32 muy pronto, pues se espera que en junio los desarrolladores ya tengan acceso a una versión de ambos programas con compatibilidad con el nuevo modo de cálculo.
Por último, pero no menos importante, los Tensor Cores han ayudado mediante TF32 a solucionar operaciones FP64 de forma más veloz mediante lo que se conoce como solucionadores lineales, unos algoritmos que permiten hacer uso de operaciones FP32 y que, como es de esperar también se van a ver beneficiados por las mejoras en rendimiento que supone el uso de los Tensor Cores en vez de los métodos tradicionales a través de una unidad de coma flotante.
Doble precisión y Matrix Math
Hemos hablado ya varias veces de las matrices de operaciones en este artículo, y es que se trata de los modelos numéricos utilizados, por ejemplo, para crear simulaciones como serían el análisis de proteínas para el desarrollo de una vacuna, o la simulación de fuerzas a la hora de diseñar un avión desde cero.
Los cálculos utilizados para ello se denominan cálculos de coma flotante de precisión doble, comúnmente conocidos como FP64, y se trata de uno de los modos de cómputo más intensivos para el hardware de entre todos los que existen, razón por la que NVIDIA ha aprovechado los Tensor Cores de tercera generación para acelerar los cálculos FP64 en 2.5 veces respecto a Volta.
Asimismo, el propio flujo de la creación de una simulación queda modificado desde el principio. En él, una simulación inicial crea un dataset que entrena un modelo de Inteligencia Artificial. En este punto, tanto el modelo artificial como la simulación funcionan de forma conjunta, compartiendo los puntos en común entre los resultados de las simulaciones y del aprendizaje realizado por la inteligencia artificial hasta que el modelo está listo para proporcionar resultados en tiempo real a través de inferencia, siendo este proceso el que se conoce como entrenamiento
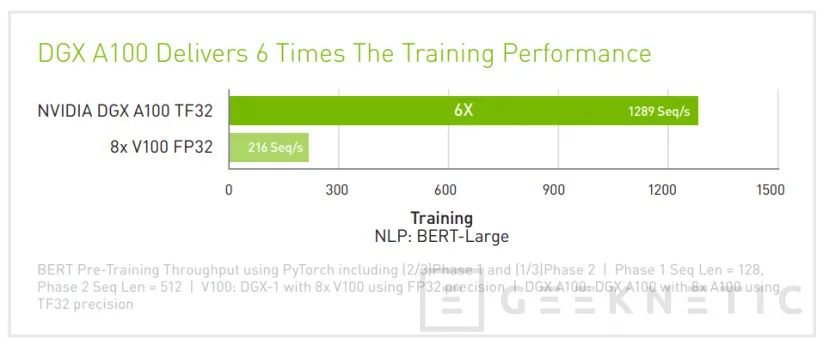
De este modo, se reduce el número de instancias de la simulación que deben ejecutarse gracias a que la propia inteligencia artificial puede definir algunas áreas de interés que eliminan la necesidad de realizar ciertas simulaciones, mientras que las que sí deben realizarse, se aceleran en 2.5 veces como ya hemos mencionado.
Por otra parte, las librerías CUDA-X se han visto actualizadas para que los usuarios tengan acceso a las capacidades de aceleración FP64 en la arquitectura Ampere, especialmente DMMA, un nuevo modo que permite acelerar las operaciones de matriz FP64.
Una sola instancia DMMA utiliza una instrucción para sustituir ocho instrucciones FP64 tradicionales, algo que le permite al NVIDIA A100 procesar cálculos de doble precisión mucho más rápido y con menos esfuerzo que otros chips, ahorrando no solo tiempo y energía en el proceso, sino también memoria y ancho de banda I/O.
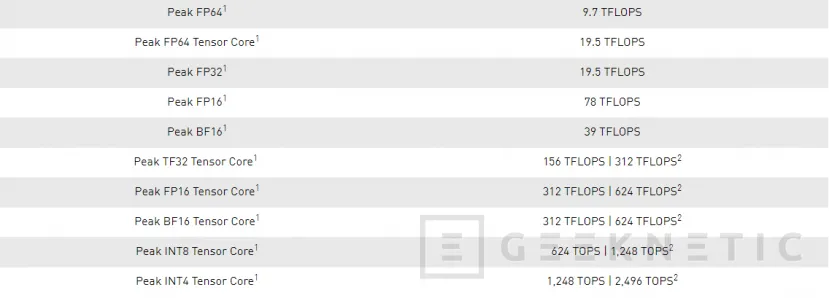
NVIDIA llama a esto “Double-Precision Tensor Cores”, algo que proporciona la potencia de los Tensor Cores de tercera generación a las aplicaciones HPC que lo necesiten al hacer uso de cálculos de matriz repetitivos, algo en lo que NVIDIA ha hecho hincapié a la hora de hacer funcionar dado que se usa en multitud de campos como dinámica de fluidos, salud, o ciencias de materiales y energía nuclear.
Por último, la tercera generación de los Tensor Cores da soporte a matrices de mayor tamaño, de 8x8x4, en comparación a las matrices de 4x4x4 que encontramos en Volta, algo que permite a los usuarios enfrentarse a problemas matemáticos más grandes.
Modo MIG (Multi Instance GPU)
Otra de las interesantes novedades que encontramos en Ampere es la posibilidad de dividir la GPU en diferentes partes para permitir que diferentes usuarios hagan uso de la misma como si de unidades separadas se refiriese, algo muy interesante, especialmente teniendo en cuenta que en la conferencia de lanzamiento pudimos ver como cada división de la GPU era capaz de rendir como una GPU Volta al completo en determinadas tareas como eran la inferencia.
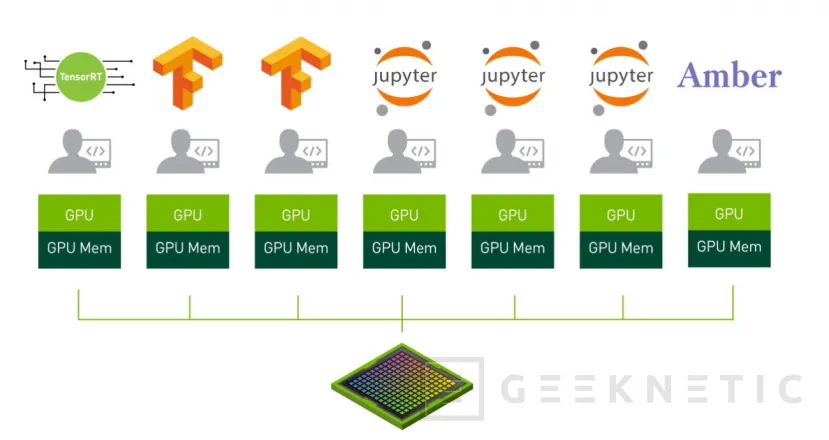
MIG permite, de este modo, particionar los SM y su correspondiente memoria en los GPC que hemos visto anteriormente, que se encuentran conectados a todo lo necesario para funcionar de forma independiente entre sí, permitiendo asignar, en el caso de la A100, un mínimo de 1 GPC con 14 Stream Multiprocessors, que cuenta con un total de 896 CUDA Cores y 56 Tensor Cores junto a 5GB de memoria HBM2.
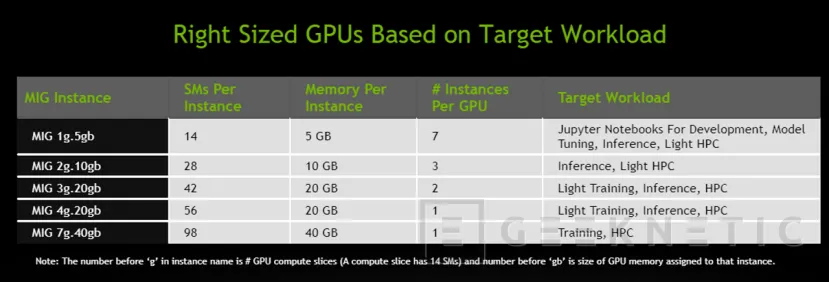
Esto permite también una mayor calidad en el servicio, asegurando que ninguna instancia se va a ver afectada por problemas que puedan afectar a una instancia colindante, como sería un bloqueo de algún tipo, o por ejemplo desplegar trabajos de inferencia que no necesitan de la potencia de una GPU completa pero que sí pueden funcionar en paralelo, aumentando así el rendimiento sin tener que recurrir a una GPU adicional.
Sparsity
Las nuevas GPU Ampere de NVIDIA son capaces con lo que se denomina en inteligencia artificial como sparsity, una forma de retirar de una red neural el mayor número de parámetros posibles sin afectar a la precisión de la inteligencia artificial completa.
La meta de esta característica es reducir la cantidad de multiplicaciones que una matriz de aprendizaje profundo requiere, reduciendo el tiempo para obtener buenos resultados, algo que hasta ahora no había sido posible realizar de forma consistente sin perder precisión en la red neural.
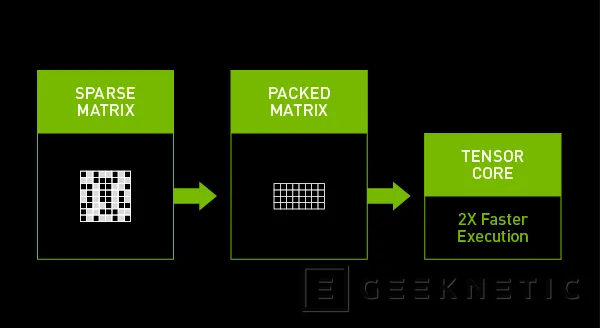
La técnica de NVIDIA se vale de los Tensor Cores de tercera generación para reducir las redes neuronales, eliminando esencialmente los valores que tienen la menor importancia o son ubicaciones de valor cero, los cuales puedes saltarse directamente.
Una vez reducidos estos valores, la GPU A100 automatiza el resto del trabajo, comprimiendo la matriz para procesarla al doble de velocidad de lo que lo haríamos si trabajamos con una matriz densa.
NVIDIA HGX A100
Todo lo contado hasta ahora nos lleva a la NVIDIA HGX A100, la plataforma para centro de datos que llega en dos versiones, una con 4 GPUs conectadas entre sí mediante NVLink y otra con 8 GPUs conectadas a través de NVSwitches.
NVIDIA HGX A100 8-GPU
Por una parte, la plataforma de 8 GPUs es capaz de que todas las GPUs se puedan comunicar entre sí a una velocidad bidireccional de 600GB/s, algo 10 veces mayor que el bus PCI Express 4.0 x16 más rápido, y que además permite que dos de estas placas base puedan conectarse entre sí, algo que expande el tamaño de la malla hasta las 16 GPUs Ampere.

Para crear la plataforma HGX A100 8-GPU, NVIDIA ha utilizado dos procesadores de la gama de servidores de AMD, algo que ha permitido a la compañía contar con un mínimo de cuatro enlaces PCI Express 4.0 x16 para asegurar que existe suficiente ancho de banda para alimentar a todas las GPUs de datos que procesar.
No todo es potencia de cómputo, razón por la que podemos encontrar conectados en cada NVSwitch dos NIC Mellanox ConnectX-6 200Gb/s junto a almacenamiento NVMe, siendo ambos componentes completamente accesibles desde la GPU gracias a GPUDirect, reduciendo así la latencia de las comunicaciones entre las distintas GPUs o la red en la que se puedan encontrar otros nodos realizando la misma tarea en escala.
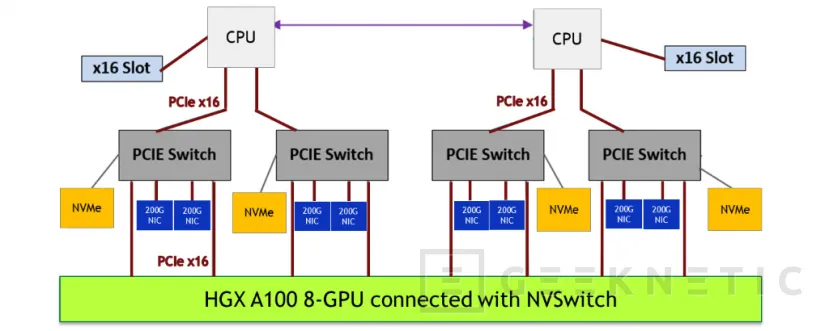
Los beneficios que otorga contar con un diseño basado en NVSwitches incluyen el hecho de ser más sencillos de programar, especialmente gracias a que cualquier GPU NVIDIA A100 puede comunicarse a 600GB/s con cualquiera de las GPUs en la misma placa base, además de permitir trabajar con modelos IA mucho más grandes al permitir dividirlos y distribuirlos entre diferentes GPUs conectadas entre sí.
NVIDIA HGX A100 4-GPU
Este diseño, por el contrario, no cuenta con NVSwitches, algo que si tomamos lo que acabamos de referenciar podría considerarse un problema, pero no necesariamente tiene que serlo si los requisitos apoyan una configuración NVLink. En este caso, algunas aplicaciones científicas necesitan una mayor capacidad de CPU que otras, algo que en el caso del modelo con cuatro GPUs queda más compensado al seguir contando con dos procesadores, o lo que es lo mismo, cada procesador puede alimentar con soltura a dos GPUs.

Asimismo, en ocasiones la infraestructura eléctrica existente en algunos centros de datos limita la potencia disponible por cada rack, de forma que en estos casos una plataforma con un consumo de energía menor es preferible.
Por último, algunos administradores asignan recursos con una granularidad de un nodo, algo que en el caso de los HGX de 4 GPUs permite que cada nodo tenga la mitad de potencia que los modelos con 8GPUs, doblando así la granularidad de la asignación de recursos al poderse siempre sumar dos nodos de 4GPUs para crear un nodo de 8GPUs, pero no a la inversa.
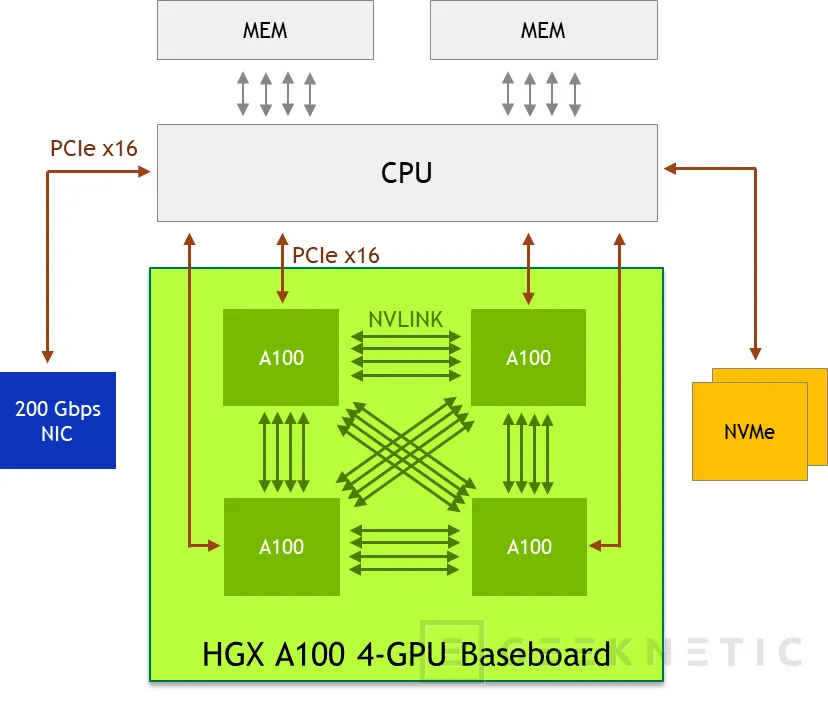
Los cambios arquitecturales entre los dos HGX, por tanto, aparecen entorno a la ausencia de los NVSwitches, pues en esta ocasión tanto el almacenamiento NVMe como la interfaz de red se encuentran conectados al procesador, aunque sigue permitiendo utilizar GPUDirect para obtener acceso directo al almacenamiento desde el sistema de GPUs.
NVIDIA DGX A100
Por último, nos encontramos con el NVIDIA DGX A100, un equipo completamente montado que nos permite contar con una plataforma HGX A100 completa con 8 GPUs y todos los dispositivos auxiliares necesarios para contar con tantos nodos DGX como sea necesario para nuestra carga de trabajo.
|
NVIDIA DGX A100 | |
|---|---|
|
GPUs |
8x NVIDIA A100 Tensor Core GPUs |
|
Memoria GPU |
8x 40GB HBM2, total 320GB |
|
Rendimiento |
5 petaFLOPS AI 10 petaOPS INT8 |
|
NVIDIA NVSwitches |
6 |
|
Consumo máximo del sistema |
6500W |
|
CPU |
2x AMD EPYC 7742, total 128 núcleos/256 hilos, 2.25GHz base, 3.4GHz boost |
|
Memoria RAM |
1TB |
|
Conectividad de red |
8x Single-Port Mellanox ConnectX-6 VPI 200Gb/s HDR Infiniband 1x Dual-Port Mellanox ConnectX-6 VPI 10/25/50/100/200Gb Ethernet |
|
Almacenamiento |
Sistema operativo: 2x 1.92TB M.2. NVMe |
|
Almacenamiento interno: 15TB (4x3.84TB) U.2. NVMe | |
|
Sistema operativo |
Ubuntu |
|
Peso y dimensiones |
Peso: 123KG Altura: 264mm (6U) Ancho: 482.3mm (19 pulgadas) Profundidad: 897.1mm |
Los NVIDIA DGX 100 pueden ser montados en armarios rack para apilar varias unidades y hacerlos funcionar de forma conjunta, formando así un clúster que, llegado el rendimiento y tamaño necesarios, puede funcionar como un superordenador, configuración que NVIDIA asegura que se puede entregar como un paquete completamente integrado y listo para desplegar debido a la complejidad de su configuración, como sería por ejemplo el caso de los NVIDIA DGX SuperPOD.

Fin del Artículo. ¡Cuéntanos algo en los Comentarios!








