

Explicamos las mejoras de rendimiento en shaders con la llegada de DirectX12
por Mikel Aguirre 5
Se está hablando mucho últimamente sobre las tecnologias y mejoras que tendrán la API DirectX 12 que llegará con Windows 10.
Hasta ahora sabíamos que DirectX 12 iba a mejorar de forma considerable la comunicación entre la CPU y la GPU proporcionando un aumento de rendimiento de hasta un 60%. Es lo que pudimos ver en las demos del pasado mes de agosto: Demo de DirectX 12.
AMD ha detallado una de las claves de las mejoras de rendimiento en DirectX 12, que consiste en el procesamiento asíncrono de la cola de comandos de los shaders.
Partimos de la base de que hay 3 tipos de colas de instrucciones que se procesan en los shaders: la cola de gráficos, la cola de computación y la cola de copias. Estas colas de procesamiento deben unirse en la cola principal de procesamiento de los shaders.
En DirectX 11 la forma de unir estas 3 colas en una es síncrona. Es decir, se van alternando los distintos comandos de cada cola en la cola principal, primero de una cola, luego de otra y luego de otra, de forma síncrona. La cuestión es que en el procesamiento de gráficos multihilo algunos comandos sólo se generan después de la ejecución de otros en otra cola de procesamiento. Eso hace que haya espacios de procesamiento vacíos en la cola de procesamiento principal, lo que supone que los shaders nunca estén trabajando al 100% de su potencial.

Una de las soluciones disponibles en DirectX 11 es la priorización de comandos. Si llega un comando urgente a alguna de las colas de comando, se paraliza lo que se está procesando en la cola principal para dar paso al comando urgente. Pero esto puede hacer que el rendimiento empeore debido a un exceso en las órdenes de intercambio de una cola a otra para la ejecución de dichas tareas prioritarias. Además esto tampoco hacía que se llenasen todos los huecos de la cola de procesamiento.
El procesamiento asíncrono de la API de DirextX 12 consiste en un cambio en la forma de introducir los comandos de las distintas colas en la cola de procesamiento principal. En lugar de tener un conmutador síncrono de colas para meterlas en la cola principal, los comandos de cada cola se van intercalando en la cola principal en función de los huecos disponibles.

Esto significa que cada cola de comandos puede introducir comandos en la cola de procesamiento principal sin esperar a que se completen otras tareas. En otras palabras, reducimos considerablemente los huecos libres sin procesar de la cola de comandos principal, lo que aumenta considerablemente el uso de la GPU y en consecuencia puede mejorar el rendimiento en determinadas situaciones.
Además esta solución sigue permitiendo la priorización de comandos cuando resulta necesario.
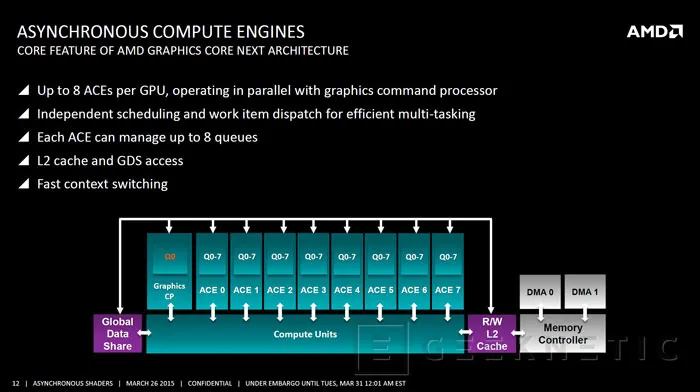
En el caso de las GPUs GCN de AMD, cada ACE (Asynchronous Compute Engine) puede hacerse cargo de hasta 8 colas de comandos. Las GPUs más básicas tienen un par de ACEs mientras que las GPUs más elaboradas pueden disponer de 8.
En una demo del SDK del LiquidVR, con el procesamiento asíncrono deshabilitado y el post-procesamiento activo, se obtuvieron 158 FPS. Sin embargo cuando habilitamos el procesamiento asíncrono sube a los 230FPS. Estaríamos hablando de una mejora del 45% en el rendimiento de esta demo.
Esta mejora resulta especialmente interesante para realidad virtual en dispositivos como el Oculus Rift, donde se requieren generar un gran número de frames de la forma más rápida posible.
Sin embargo teniendo en cuenta que un mismo frame no se puede rasterizar y postprocesar al mismo tiempo, el procesamiento asíncrono genera mayor latencia en la GPU con respecto al procesamiento síncrono. En cualquier caso hay situaciones en que este exceso de latencia puede ser un mal menor si obtenemos un mayor volumen de frames por segundo.
En cualquier caso, tenemos que tener en cuenta que esto no tiene por qué traducirse en un 45% de mejora instantánea porque un juego sea DirectX 12. Aunque éste sea un buen avance tenemos que tener en cuenta que a día de hoy los motores gráficos que hay en el mercado hacen muy bien su trabajo ya no dejan tantos espacios sin cubrir en la cola de procesamiento como lo hacían antes.
Tanto las GPUs Maxwell de NVIDIA (serie 9XX) como las GPUs GCN de AMD están preparadas para el procesamiento asíncrono en shaders a través de la API de DirectX 12.
Los shaders asíncronos no son algo nuevo, ya existen en la API Mantle de AMD, en Vulkan y en la API de LiquidVR desde hace algun tiempo. Nos consta que AMD ha tenido mucho que ver en la incorporación de los shaders asíncronos a la API de Microsoft. Pronto podremos ver cuál de los dos gigantes de los gráficos sacan mayor partido a la API de DirectX 12.
Fin del Artículo. ¡Cuéntanos algo en los Comentarios!








